《Unity3D高级编程之进阶主程》第一章,C#要点技术(二) - Dictionary 底层源码剖析
前文剖析了 List 的源码,我们明白了 List 是用数组构建而成的,增加,减少,插入的操作,都在数组中进行。我们还分析了大部分 List 的接口,包括Add,Remove,Insert,IndexOf,Find,Sort,ToArray,等等。我们得出了一个结论,List 是一个兼容性比较好的组件,但 List 在效率方面并没有做优化,线程也并不安全,需要加锁机制来保证线程的安全性。
===
这次我们来对常用的另一个组件 Dictionary 组件进行底层源码的分析,看看我们常用的字典容器是如何构造而成的,它的优缺点如何。
Dictionary 底层代码
我们知道 Dictionary 字典型数据结构,是以关键字Key 和 值Value 进行一一映射的。Key的类型并没有做任何的限制,可以是整数,也可以是的字符串,甚至可以是实例对象。关键字Key是如何映射到内存的呢?
其实没有什么神秘的,这种映射关系可以用一个Hash函数来建立,Dictionary 也确实是这样做的。这个Hash函数也并非神秘,我们可以简单的认为它只是做了一个模(Mod余)的操作,Dictionary 将每个Key加入容器的元素都要进行一次Hash哈希的运算操作,从而找到自己的位置。
Hash函数可以有很多种算法,最简单的可以认为是余操作,比如当Key为整数93时
hash_key = Key % 30 = 3
对于对象和字符串来说,虽然没有直接点数字做标准,但也能以实例ID为标准来做Hash操作。实际算法可能没有我举例子这么简单,我们将在下面的源码剖析中详细讲解。
对于不同的关键字可能得到同一哈希地址,即
key1 != key2 => F(key1)=F(fey2)
这种现象叫做Hash哈希冲突,在一般情况下,冲突只能尽可能的少,而不能完全避免。因为哈希函数是从关键字范围到索引范围的映射,通常关键字范围要远大于索引范围,它的元素包括多个可能的关键字。既然如此,如何处理冲突则是构造哈希表不可不解决的一个问题。
在处理Hash哈希冲突的方法中通常有:开放定址法、再哈希法、链地址法、建立一个公共溢出区等。Dictionary使用的解决冲突方法是拉链法,又称链地址法。
拉链法的原理:
将所有关键字为同义词的结点链接在同一个单链表中。若选定的散列表长度为n,则可将散列表定义为一个由n个头指针组成的指针数 组T[0..n-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。
在哈希表上进行查找的过程,和,在哈希表构建的过程是基本一致的。
给定Key值,根据造表时设定的哈希函数求得哈希地址,若表中此位置没有记录,则查找不成功;否则比较关键字,若何给定值相等,则查找成功;否则根据处理冲突的方法寻找“下一地址”,直到哈希表中某个位置为空或者表中所填记录的关键字等于给定值时为止。
我们来看看更形象的结构图,如下:
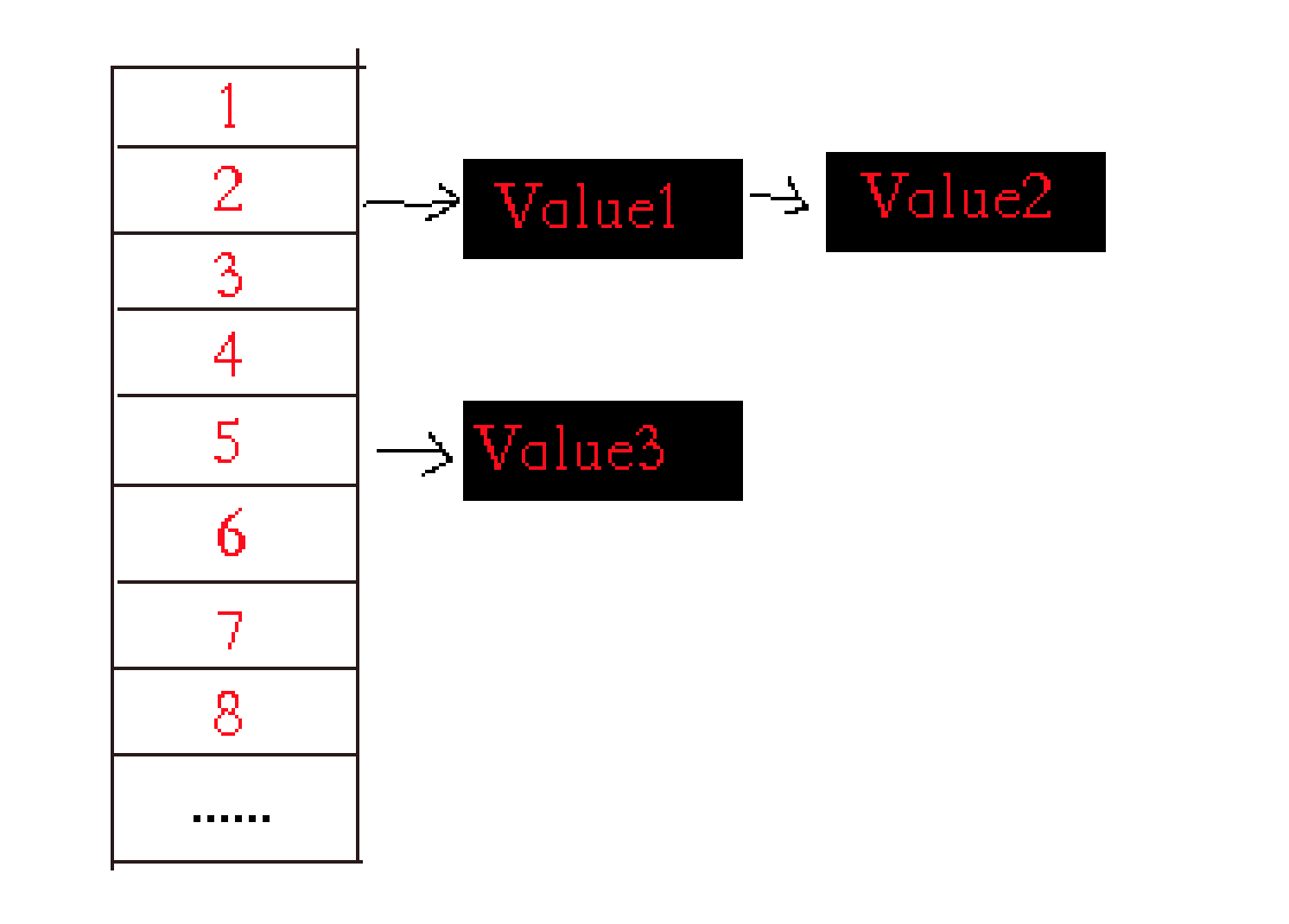
如图所示,拉链法结构中,主要的宿主为数组指针,每个数组元素里存放着指向下一个节点的指针,如果没有元素在单元上,则为空指针。当多个元素都指向同一个单元格时,则以链表的形式依次存放并列的元素。
在 Dictionary 中究竟是如何实现的呢,我们来剖析一下源码。
首先我们来看看源码中对 Dictionary 的变量定义部分,如下:
public class Dictionary<TKey,TValue>: IDictionary<TKey,TValue>, IDictionary, IReadOnlyDictionary<TKey, TValue>, ISerializable, IDeserializationCallback
{
private struct Entry {
public int hashCode; // Lower 31 bits of hash code, -1 if unused
public int next; // Index of next entry, -1 if last
public TKey key; // Key of entry
public TValue value; // Value of entry
}
private int[] buckets;
private Entry[] entries;
private int count;
private int version;
private int freeList;
private int freeCount;
private IEqualityComparer<TKey> comparer;
private KeyCollection keys;
private ValueCollection values;
private Object _syncRoot;
}
从继承的类和接口看,Dictionary 主要继承了 IDictionary 接口,和 ISerializable 接口。IDictionary 和 ISerializable 在使用过程中,其主要的接口为,Add, Remove, ContainsKey, Clear, TryGetValue, Keys, Values, 以及[]数组符号形式作为返回值的接口。也包括了常用库 Collection 中的接口,Count, Contains等。
从 Dictionary 的定义变量中可以看出,Dictionary 是以数组为底层数据结构的类。当我们实例化 new Dictionary() 后,内部的数组是0个数组的状态。与 List 组件一样,Dictionary 也是需要扩容的,会随着元素数量的增加而不断扩容。具体我们来看看下面的接口源码剖析。
下面的我们将围绕上述的接口进行解析 Dictionary 底层运作机制。
了解Add是最直接了解底层数据结构如何运作的途径,我们来看下Add接口的实现。
源代码如下:
public void Add(TKey key, TValue value)
{
Insert(key, value, true);
}
private void Initialize(int capacity)
{
int size = HashHelpers.GetPrime(capacity);
buckets = new int[size];
for (int i = 0; i < buckets.Length; i++) buckets[i] = -1;
entries = new Entry[size];
freeList = -1;
}
private void Insert(TKey key, TValue value, bool add)
{
if( key == null ) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets == null) Initialize(0);
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int targetBucket = hashCode % buckets.Length;
#if FEATURE_RANDOMIZED_STRING_HASHING
int collisionCount = 0;
#endif
for (int i = buckets[targetBucket]; i >= 0; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {
if (add) {
ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate);
}
entries[i].value = value;
version++;
return;
}
#if FEATURE_RANDOMIZED_STRING_HASHING
collisionCount++;
#endif
}
int index;
if (freeCount > 0) {
index = freeList;
freeList = entries[index].next;
freeCount--;
}
else {
if (count == entries.Length)
{
Resize();
targetBucket = hashCode % buckets.Length;
}
index = count;
count++;
}
entries[index].hashCode = hashCode;
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
buckets[targetBucket] = index;
version++;
#if FEATURE_RANDOMIZED_STRING_HASHING
#if FEATURE_CORECLR
// In case we hit the collision threshold we'll need to switch to the comparer which is using randomized string hashing
// in this case will be EqualityComparer<string>.Default.
// Note, randomized string hashing is turned on by default on coreclr so EqualityComparer<string>.Default will
// be using randomized string hashing
if (collisionCount > HashHelpers.HashCollisionThreshold && comparer == NonRandomizedStringEqualityComparer.Default)
{
comparer = (IEqualityComparer<TKey>) EqualityComparer<string>.Default;
Resize(entries.Length, true);
}
#else
if(collisionCount > HashHelpers.HashCollisionThreshold && HashHelpers.IsWellKnownEqualityComparer(comparer))
{
comparer = (IEqualityComparer<TKey>) HashHelpers.GetRandomizedEqualityComparer(comparer);
Resize(entries.Length, true);
}
#endif // FEATURE_CORECLR
#endif
}
展示的代码稍稍多了点,我们摘出其中的要点,通过要点来了解重点,再通过重点了解全局。
其实 Add 接口就是 Insert 的代理,因为它 Insert 一句话,那么 Inset 里做了什么呢?
首先在加入数据前需要对数据结构进行构造。
if (buckets == null) Initialize(0);
其实在 Dictionary 构建时如果没有指定任何数量 buckets 就有可能是空的,所以需要对buckets进行初始化,Initialize(0),说明构建的数量级最少。
不过奥妙就在 Initialize 函数里,如果传入的参数不是0,而是5、10、25、或其他更大的数量的话,那么构造多大的数据结构才合适呢?
在 Initialize 函数中,给了我们答案,看下面这行:
int size = HashHelpers.GetPrime(capacity);
它们有专门的方法来计算到底该使用多大的数组,我们查出源码 HashHelpers 中,primes数值是这样定义的:
public static readonly int[] primes = {
3, 7, 11, 17, 23, 29, 37, 47, 59, 71, 89, 107, 131, 163, 197, 239, 293, 353, 431, 521, 631, 761, 919,
1103, 1327, 1597, 1931, 2333, 2801, 3371, 4049, 4861, 5839, 7013, 8419, 10103, 12143, 14591,
17519, 21023, 25229, 30293, 36353, 43627, 52361, 62851, 75431, 90523, 108631, 130363, 156437,
187751, 225307, 270371, 324449, 389357, 467237, 560689, 672827, 807403, 968897, 1162687, 1395263,
1674319, 2009191, 2411033, 2893249, 3471899, 4166287, 4999559, 5999471, 7199369};
public static int GetPrime(int min)
{
if (min < 0)
throw new ArgumentException(Environment.GetResourceString("Arg_HTCapacityOverflow"));
Contract.EndContractBlock();
for (int i = 0; i < primes.Length; i++)
{
int prime = primes[i];
if (prime >= min) return prime;
}
//outside of our predefined table.
//compute the hard way.
for (int i = (min | 1); i < Int32.MaxValue;i+=2)
{
if (IsPrime(i) && ((i - 1) % Hashtable.HashPrime != 0))
return i;
}
return min;
}
// Returns size of hashtable to grow to.
public static int ExpandPrime(int oldSize)
{
int newSize = 2 * oldSize;
// Allow the hashtables to grow to maximum possible size (~2G elements) before encoutering capacity overflow.
// Note that this check works even when _items.Length overflowed thanks to the (uint) cast
if ((uint)newSize > MaxPrimeArrayLength && MaxPrimeArrayLength > oldSize)
{
Contract.Assert( MaxPrimeArrayLength == GetPrime(MaxPrimeArrayLength), "Invalid MaxPrimeArrayLength");
return MaxPrimeArrayLength;
}
return GetPrime(newSize);
}
上述代码为 HashHelpers 部分的源码,其中 GetPrime 会返回一个需要的 size 最小的数值,从 GetPrime 函数的代码中,我们可以知道这个 size 是由数组 primes 里的值与当前需要的数量大小有关,当需要的数量小于 primes 某个单元格的数字时返回该数字,而 ExpandPrime 则更加简单粗暴,直接返回原来size的2倍作为扩展数量。
从Prime的定义看的出,首次定义size为3,每次扩大2倍,也就是,3->7->17->37->…. 底层数据结构的大小是按照这个数值顺序来扩展的,除非你在创建 Dictionary 时,先定义了他的初始大小,指定的初始大小也会先被 GetPrime 计算该分配的数量最终得到应该分配的数组大小。这和 List 组件的分配方式一模一样。
我们继续看初始化后的内容,对关键字 Key 做Hash哈希操作从而获得地址索引:
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int targetBucket = hashCode % buckets.Length;
当调用函数获得Hash哈希值后,还需要对哈希地址做余操作,以确定地址落在 Dictionary 数组长度范围内不会溢出。
紧接着对指定数组单元格内的链表元素做遍历操作,找出空出来的位置将值填入。
for (int i = buckets[targetBucket]; i >= 0; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {
if (add) {
ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate);
}
entries[i].value = value;
version++;
return;
}
#if FEATURE_RANDOMIZED_STRING_HASHING
collisionCount++;
#endif
}
这一步就是前面我们所说的拉链法的链表推入动作。当获得Hash值的数组索引后,我们知道了该将数据存放在哪个数组位置上,如果该位置已经有元素被推入,则需要将其推入到链表的尾部。从for循环开始,检查是否到达链表的末尾,最后将数据放入尾部,并结束函数。
如果数组的空间不够了怎么办?源码中体现了这一点:
int index;
if (freeCount > 0) {
index = freeList;
freeList = entries[index].next;
freeCount--;
}
else {
if (count == entries.Length)
{
Resize();
targetBucket = hashCode % buckets.Length;
}
index = count;
count++;
}
entries[index].hashCode = hashCode;
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
buckets[targetBucket] = index;
当被用来记录剩余单元格数量的变量 freeCount 等于0时,则进行扩容,扩容后的大小就是我们前面提到的 调用 ExpandPrime 后的数量,即通常情况下为原来的2倍,再根据这个空间大小数字调用 GetPrime 来得到真正的新数组的大小。
了解了Add接口,我们来看看Remove部分。
删除的过程和插入的过程比较相似,因为要查找到Key元素所在位置,所以再次将Key值做哈希操作也是难免的,然后类似沿着拉链法的模式寻找与关键字匹配的元素。
Remove 用关键字删除元素的接口源码:
public bool Remove(TKey key)
{
if(key == null) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null) {
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int bucket = hashCode % buckets.Length;
int last = -1;
for (int i = buckets[bucket]; i >= 0; last = i, i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {
if (last < 0) {
buckets[bucket] = entries[i].next;
}
else {
entries[last].next = entries[i].next;
}
entries[i].hashCode = -1;
entries[i].next = freeList;
entries[i].key = default(TKey);
entries[i].value = default(TValue);
freeList = i;
freeCount++;
version++;
return true;
}
}
}
return false;
}
我们注意到 Remove 接口相对 Add 接口简单的多,同样用哈希函数 comparer.GetHashCode 再除余后得到范围内的地址索引,再做余操作确定地址落在数组范围内,从哈希索引地址开始,查找冲突的元素的Key是否与需要移除的Key值相同,相同则进行移除操作并退出。
注意源码中,Remove 的移除操作并没有对内存进行删减,而只是将其单元格置空,这是位了减少了内存的频繁操作。
我们继续剖析另一个重要的接口 ContainsKey 检测是否包含关键字的接口。源码如下:
public bool ContainsKey(TKey key)
{
return FindEntry(key) >= 0;
}
private int FindEntry(TKey key)
{
if( key == null) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null) {
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
for (int i = buckets[hashCode % buckets.Length]; i >= 0; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) return i;
}
}
return -1;
}
从源码中看到 ContainsKey 是一个查找Key位置的过程。它调用了 FindEntry 函数,FindEntry 查找Key值位置的方法跟我们前面提到的相同。从用Key值得到的哈希值地址开始查找,查看所有冲突链表中,是否有与Key值相同的值,找到即刻返回该索引地址。
有了前面对几个核心接口理解的基础,其他接口相对比较就简单多了,我们快速的看过去。
TryGetValue 尝试获取值的接口:
public bool TryGetValue(TKey key, out TValue value)
{
int i = FindEntry(key);
if (i >= 0) {
value = entries[i].value;
return true;
}
value = default(TValue);
return false;
}
与 ContainsKey 同样,他调用的也是FindEntry的接口,来获取Key对应的Value值。
对[]操作符的重定义,源码:
public TValue this[TKey key] {
get {
int i = FindEntry(key);
if (i >= 0) return entries[i].value;
ThrowHelper.ThrowKeyNotFoundException();
return default(TValue);
}
set {
Insert(key, value, false);
}
}
在重新定义[]符号的代码中,获取元素时也同样使用 FindEntry 函数,而 Set 设置元素时则使用与 Add 调用相同的 Insert函数,它们都是同一套方法,即哈希拉链冲突解决方案。
从源码剖析来看,哈希冲突的拉链法贯穿了整个底层数据结构。因此哈希函数是关键了,哈希函数的好坏直接决定了效率高低。
既然这么重要,我们来看看哈希函数的创建过程,比较函数的创建的源码:
private static EqualityComparer<T> CreateComparer()
{
Contract.Ensures(Contract.Result<EqualityComparer<T>>() != null);
RuntimeType t = (RuntimeType)typeof(T);
// Specialize type byte for performance reasons
if (t == typeof(byte)) {
return (EqualityComparer<T>)(object)(new ByteEqualityComparer());
}
// If T implements IEquatable<T> return a GenericEqualityComparer<T>
if (typeof(IEquatable<T>).IsAssignableFrom(t)) {
return (EqualityComparer<T>)RuntimeTypeHandle.CreateInstanceForAnotherGenericParameter((RuntimeType)typeof(GenericEqualityComparer<int>), t);
}
// If T is a Nullable<U> where U implements IEquatable<U> return a NullableEqualityComparer<U>
if (t.IsGenericType && t.GetGenericTypeDefinition() == typeof(Nullable<>)) {
RuntimeType u = (RuntimeType)t.GetGenericArguments()[0];
if (typeof(IEquatable<>).MakeGenericType(u).IsAssignableFrom(u)) {
return (EqualityComparer<T>)RuntimeTypeHandle.CreateInstanceForAnotherGenericParameter((RuntimeType)typeof(NullableEqualityComparer<int>), u);
}
}
// See the METHOD__JIT_HELPERS__UNSAFE_ENUM_CAST and METHOD__JIT_HELPERS__UNSAFE_ENUM_CAST_LONG cases in getILIntrinsicImplementation
if (t.IsEnum) {
TypeCode underlyingTypeCode = Type.GetTypeCode(Enum.GetUnderlyingType(t));
// Depending on the enum type, we need to special case the comparers so that we avoid boxing
// Note: We have different comparers for Short and SByte because for those types we need to make sure we call GetHashCode on the actual underlying type as the
// implementation of GetHashCode is more complex than for the other types.
switch (underlyingTypeCode) {
case TypeCode.Int16: // short
return (EqualityComparer<T>)RuntimeTypeHandle.CreateInstanceForAnotherGenericParameter((RuntimeType)typeof(ShortEnumEqualityComparer<short>), t);
case TypeCode.SByte:
return (EqualityComparer<T>)RuntimeTypeHandle.CreateInstanceForAnotherGenericParameter((RuntimeType)typeof(SByteEnumEqualityComparer<sbyte>), t);
case TypeCode.Int32:
case TypeCode.UInt32:
case TypeCode.Byte:
case TypeCode.UInt16: //ushort
return (EqualityComparer<T>)RuntimeTypeHandle.CreateInstanceForAnotherGenericParameter((RuntimeType)typeof(EnumEqualityComparer<int>), t);
case TypeCode.Int64:
case TypeCode.UInt64:
return (EqualityComparer<T>)RuntimeTypeHandle.CreateInstanceForAnotherGenericParameter((RuntimeType)typeof(LongEnumEqualityComparer<long>), t);
}
}
// Otherwise return an ObjectEqualityComparer<T>
return new ObjectEqualityComparer<T>();
}
我们看到源码中,对数字,byte,有‘比较’接口(IEquatable<T>),和没有‘比较’接口,四种方式进行了区分对待。
对于像数字和byte类的,比较容易比较,所以它们都是一类,且是有相应固定的比较函数的。而有‘比较’接口(IEquatable<T>)的实体,则直接使用GenericEqualityComparer<T>来获得哈希函数。最后那些没有‘比较’接口(IEquatable
在C#里所有类都继承了 Object 类,所以即使没有特别的重写 Equals 函数,都会使用 Object 类的 Equals 函数:
public virtual bool Equals(Object obj)
{
return RuntimeHelpers.Equals(this, obj);
}
[System.Security.SecuritySafeCritical] // auto-generated
[ResourceExposure(ResourceScope.None)]
[MethodImplAttribute(MethodImplOptions.InternalCall)]
public new static extern bool Equals(Object o1, Object o2);
而这个 Equals 两个对象的比较,是以内存地址为基准的。
Dictionary 同List一样并不是线程安全的组件,官方源码中进行了这样的解释。
** Hashtable has multiple reader/single writer (MR/SW) thread safety built into
** certain methods and properties, whereas Dictionary doesn't. If you're
** converting framework code that formerly used Hashtable to Dictionary, it's
** important to consider whether callers may have taken a dependence on MR/SW
** thread safety. If a reader writer lock is available, then that may be used
** with a Dictionary to get the same thread safety guarantee.
Hashtable在多线程读写中是线程安全的,而 Dictionary 不是。如果要在多个线程中共享Dictionaray的读写操作,就要自己写lock以保证线程安全。
到这里我们已经全面了解了 Dictionary 的内部构造和运作机制。他是由数组构成,并且由哈希函数完成地址构建,由拉链法冲突解决方式来解决冲突。
从效率上看,同List一样最好在 实例化对象时,即 new 时尽量确定大致数量会更加高效,另外用数值方式做Key比用类实例方式作为Key值更加高效率。
从内存操作上看,大小以3->7->17->37->….的速度,每次增加2倍多的顺序进行,删除时,并不缩减内存。
如果想在多线程中,共享 Dictionary 则需要进行我们自己进行lock操作。
感谢您的耐心阅读
Thanks for your reading
版权申明
本文为博主原创文章,未经允许不得转载:
《Unity3D高级编程之进阶主程》第一章,C#要点技术(二) - Dictionary 底层源码剖析
Copyright attention
Please don't reprint without authorize.
微信公众号,文章同步推送,致力于分享一个资深程序员在北上广深拼搏中对世界的理解
QQ交流群: 777859752 (高级程序书友会)