《Unity3D高级编程之进阶主程》第七章,渲染管线与图形学(四) - 多重采样以及着色器编译原理
GPU上的多重采样(Multisampling)与反走样(Antialiasing)
多重采样(Multisampling)是一种对几何图元的边缘进行平滑处理的技术,也称为反走样技术之一。
OpenGL支持几种不同的反走样技术,比如多重采样、线段反走样、多边形反走样、纹理图像压缩的质量以及导数精度设置等。事实上这几种反走样技术都是以开关的形式在OpenGL中存在,我们无法修改它们只能开启关闭或设置几个简单的参数。其中图形上走样算法大致是将原本单一的线条或像素块周围填充更多的像素块,具体的填充算法细节比我们想象的要复杂的多,而且不同OpenGL的版本算法中也有细微的差异,我们在这里不深入。
多重采样也是反走样技术中的一种,它的工作方式是对每个像素的几何图元进行多次采样。在多次采样后,每个像素点不仅仅只是单个颜色(以及除了颜色外的深度值、模板值等信息),还记录了许多样本值。
这些样本值类似于将一个像素分拆成了更小型的像素,每个像素都存储着颜色、深度值、模板值等信息,当我们需要呈现最终图像的内容时,这个像素的所有样本值会被综合起来成为最终像素的颜色。也就是说采样的数量越多,线条与周围的像素点的融合越平滑,简单说就是颜色与颜色之间会有平滑过渡的颜色例如红色的线条周围是白色的背景于是红色线条上的像素与白色背景的交接处会有更多的粉色、浅粉色来过渡。
在Unity3D中对这方面的反走样功能也提供了支持,我们可以通过Quality Settings中的AntiAliasing来设置,它将开启图形接口(OpenGL或DirectX)中的多边形的反走样算法,并且开启多重采样,根据多重采样信息对多边形边缘进行像素填充。
AntiAliasing 可以设置3档采样质量分别是 2倍, 4倍 and 8倍的多重采样。
GPU上的反走样代价是消耗更多的GPU算力和显存,它并不消耗任何CPU算力。
着色器编译过程与变体
我们在知道GPU渲染管线如何运作后,对着色器编译过程仍然需要深入了解一下,我们还是以使用OpenGL为例来学习着色器在Unity3D中从编译到执行的全过程。
着色程序的编译过程与C语言等编译语言的编译过程非常类似,只是C语言在编译时是以离线的方式进行,而着色器程序的编译则是当引擎需要时,通过引擎调用图形接口(OpenGL或DirectX)的方式将代码读进来再编译,着色器程序只需要编译一次后面可以重复利用,这和我们通常所说的JIT(Just in time 即时编译)有点相似。
着色器编译前的准备工作都是Unity3D控制和执行的,当需要某个着色器程序时Unity3D引擎通过判断是否存在已经编译好的着色器程序,来决定是否编译着色器代码或是重用已经编译好的着色器程序。
那么着色程序从编译到执行过程到底是怎样的呢?让我们来了解一下。
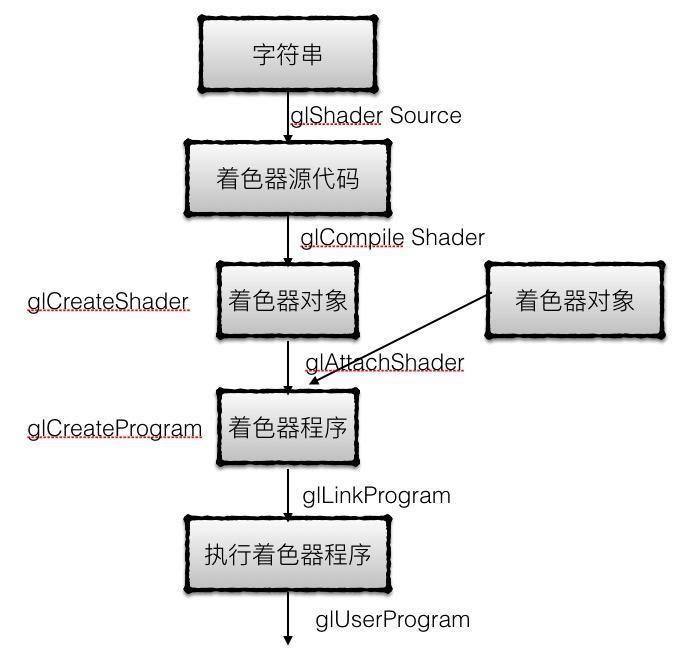
首先当Unity3D引擎得知渲染需要用到的Shader不曾被编译过时,就会调用图形接口OpenGL的 glCreateShader 为着色器创建一个新的着色器对象。
然后通过文件程序从Shader文件中获取Shader内容(字符串)并调用OpenGL的 glShaderSource 将源代码(字符串)交给刚刚创建的着色器对象上。
这时一个空的着色器对象已经关联了着色器源代码,我们可以通过调用编译接口OpenGL的 glCompileShader 对这个着色器对象进行编译。
编译完成后,我们可以通过OpenGL的 glGetShaderInfoLog 来获得编译信息以及是否成功的结果。
到此仅仅是1个着色器对象编译完成,这个着色器对象可能是顶点着色器,也可能是片元着色器,或也许是细分着色器或几何着色器。通常情况下,有好几个着色器需要编译,顶点着色器和片元着色器通常都成对出现,则会创建相应的着色器对象来分别编译它们的源代码。
有了着色器对象还不够,我们需要把这些着色器关联起来。首先Unity3D引擎会使用OpenGL的 glCreateProgram 接口需要创建一个空的着色器程序。然后多次调用 glAttachShader 来一个个地绑定着色器对象。
当所有必要的着色器对象关联到着色器程序之后,就可以链接对象来生成可执行程序了,引擎将调用OpenGL的 glLinkProgram 接口将所有关联的着色器对象生成一个完整的着色器程序。
当然,着色器对象也可能存在某些问题,因此在链接过程中依然可能失败,通常引擎会通过 glGetProgramiv 来查询链接操作的结果,也会通过 glGetProgramInfoLog 接口来获取程序链接的日志信息,由此我们就可以判断错误原因。
成功完成了着色器程序的链接后,Unity3D引擎就可以通过调用 glUseProgram 来运行着色器程序。
我们平常在Unity3D中用到的Shader中的Pass,每个Pass中都有着色器需要编译,因此每次在绘制不同的Pass时都会对Pass中的顶点着色器和片元着色器进行编译。也就是说,Unity引擎会为每个Pass标签生成一个着色器程序,生成这些着色器程序后,执行顺序仍然按照Pass的先后次序来。
现在我们了解了着色器的编译过程,它通过编译和连接的方式将一个Shader中的多个着色器制作成一个着色程序,当渲染需要时交给GPU去执行渲染。只是这样的编译过程都是在以阻塞的方式进行的,因此我们在引擎运行的过程中常常会在某针消耗些许CPU来编译Shader,如果Shader的量非常大的话可能就会有卡顿的现象发生。
Shader变体常常就会发生这种我们不希望的编译卡顿,因为它的量比较大,我们在Unity3D中使用Shader Varant(变体)时常常有比较严重的编译和内存困扰。
那么什么是“变体”呢。其实它是由Unity3D自身的宏编译指令引发的多种变化实体生成的Shader文件,它为不同情况而编译生成不同的着色器程序。从引擎端的做法来看,Unity3D把不同的编译版本拆分成了不同的着色器源代码文件,在运行时选择对应适合的着色器源文件,再通过图形接口将这些着色器源代码编译成着色器程序关联到渲染中。
为什么要使用宏编译指令导致生成这么多的着色器程序呢?因为要简化Shader,Unity3D要让一个Shader在不同材质球上的应用不同的效果时更加便捷,有了引擎识别变体的功能,我们修改和完善Shader起来会更加方便和高效。
假如没有变体,我们在编写很多同一个风格但不同效果的Shader时,在使用和维护过程中会有诸多的麻烦和不便。为了统一风格,为了提高工作效率,也为了能更好的打通各部门之间的沟通渠道,以及能让美术同学能更好的发挥对画面效果的调整,将同一个风格不同效果的Shader写在同一个Shader文件里是必不可少的,这样能更加容易的统一美术风格和制作流程,目的就是为了让风格更加统一,沟通更加便捷,效率更加高。
我们来看看Unity3D是怎么通过编译指令来编写变体的,编写变体后它是怎么生成着色器源代码的。
在Unity3D的Shader中我们使用
#pragma multi_compile
#pragma shader_feature
两个指令来实现着色器程序的自定义宏,它既适用于顶点片元着色器也适用于表面着色器。我们通过 multi_compile 指令编写例如:
#pragma multi_compile A_ON B_ON
这样会生成并编译两个Shader(变体),一个是A_ON的版本,一个是B_ON的版本。
在运行时,Unity3D会根据材质(Material)的关键字(Material的对象方法EnableKeyword和DisableKeyword)或者全局着色器关键字(Shader的类方法EnableKeyword和DisableKeyword)来选择使用对应的着色器。运行的时候Unity3D会根据材质(Material)的关键字或者Shader全局关键字判断应该使用哪个Shader,如果两个关键字都为false,那么会使用第一个(A_ON)Shader变体。
我们也可以创建多个组合关键字例如:
#pragma multi_compile A B C
#pragma multi_compile D E
这种多组合关键字会使得Shader的变体成倍的增加,例如上述的预编译方式,会生成 3x2 = 6 个变体,分别是 A+D、 B+D、 C+D、 A+E、 B+E、 C+E 六种。
假如multi_compile组合多到10行,每行2个,就是2的10次方个Shader(变体)就是1024个,这样生成这1024个Shader(变体),把这1024个变体Shader全部加载到内存的话恐怕互占用非常多的内存,1024个Shader每个50K的话就会占用50MB内存。不仅如此,实时编译Shader是非常耗时的操作,如果没有提前编译Shader而在场景中使用Shader,就会不断有不同的Shader被实时的编译,这常常是导致游戏卡顿的重要原因之一。
除了 multi_compile 之外,另外一个指令 shader_feature 也可以设置预编译宏,与 multi_compile 的区别是 shader_feature 不会将没有被使用到的Shader(变体)打包进包内,因此 shader_feature 更适合材质球的关键字指定预编译内容,因为Unity3D只生成和编译被使用的预编译情况,而 multi_compile 更适合全局Shader指定关键字,因为它会把所有组合都编译一遍,无论有没有用到。
除了这两个自定义预编译指令,Unity3D 本身自带的一些内建的 multi_compile 的快捷写法也会导致Shader变体的产生:
multi_compile_fwdbase 为前向渲染编译多个变体,不同的变体处理不同的光照贴图的计算,并且控制了主平行光的阴影的开关。
multi_compile_fwdadd 为前向渲染额外的光照部分编译多个变体,不同的变体处理不同灯光类型,平行光,聚光灯,点光,以及他们附带的cookie纹理版本。
multi_compile_fwdadd_fullshadows 和 multi_compile_fwdadd 一样,并且包含了灯光的实时阴影功能。
multi_compile_fog 为处理不同的雾效类型(off/linear/exp/exp2)扩展了多个变体。
总结,无论是 multi_compile 还是 shader_feature 亦或内建预编译指令,都会造成 Shader(变体)数量的增多,使得内存增加,运行时编译次数增多,每次编译Shader都会消耗CPU。当Unity3D在运行时检测到需要渲染的材质球里是不曾被编译的Shader时,则会将与自己匹配的Shader变体拎出来编译一下生成一个着色器程序,因此为了应对变体在运行时的编译消耗,通常会在运行时提前将所有Shader变体编译一下,使得运行中不再有Shader编译的CPU消耗。
参考文献:
《OpenGL编程指南》
《Unit3D Documentation》 https://docs.unity3d.com/Manual/SL-MultipleProgramVariants.html
感谢您的耐心阅读
Thanks for your reading
版权申明
本文为博主原创文章,未经允许不得转载:
《Unity3D高级编程之进阶主程》第七章,渲染管线与图形学(四) - 多重采样以及着色器编译原理
Copyright attention
Please don't reprint without authorize.
微信公众号,文章同步推送,致力于分享一个资深程序员在北上广深拼搏中对世界的理解
QQ交流群: 777859752 (高级程序书友会)